
Live-SWE-agent
Can Software Engineering Agents Self-Evolve on the Fly?
Leaderboard
All results are evaluated using our Live-SWE-agent scaffold. The ✓ badge indicates that results have been verified.
Submit your model's score with our scaffold for an apples-to-apples comparison!
* Unless otherwise specified, all models are evaluated with temperature=1 and high reasoning effort.
📣 News
- [Nov 24th, 2025]: Claude Opus 4.5 + Live-SWE-agent scores 79.2% on SWE-bench Verified, leading all current open-source scaffolds and coming very close to Anthropic’s internal, manually engineered scaffold for Opus 4.5!!
- [Nov 20th, 2025]: Gemini 3 Pro + Live-SWE-agent scores 77.4% on SWE-bench Verified, outperforming all available models (including Claude Sonnet 4.5) at the time of writing!
- [Nov 17th, 2025]: Claude Sonnet 4.5 + Live-SWE-agent achieves the new state-of-the-art solve rate of 45.8% on SWE-Bench Pro!
- [Nov 17th, 2025]: We've released Live-SWE-agent 1.0.0!
Live-SWE-agent
Live-SWE-agent is the first live software agent that can autonomously and continuously evolve itself on-the-fly during runtime when solving real-world software problems.
Figure below presents an overview of Live-SWE-agent.
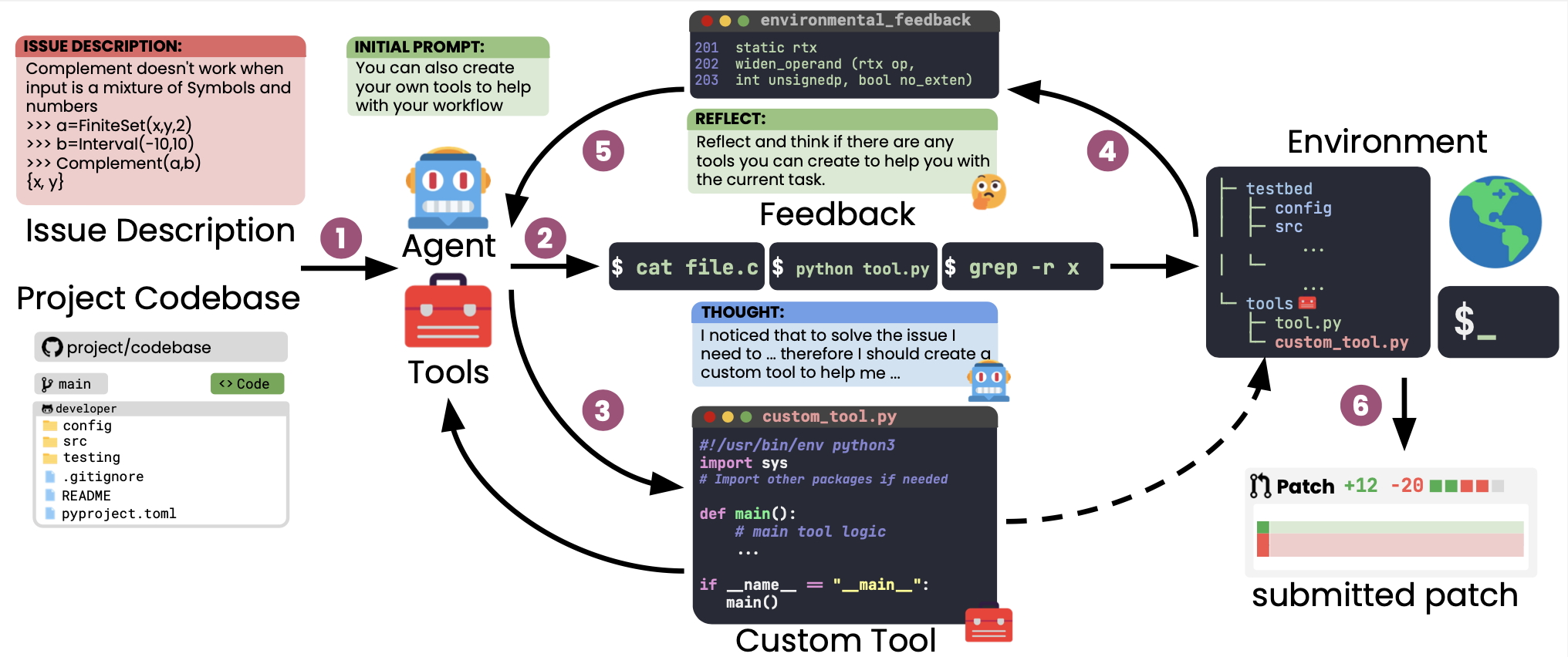
First, 1 the agent take in both the project codebase and the description of the issue to be solved with only a limited set of tools (e.g., bash commands), aiming to generate and use its own tools on the fly while solving the issue.
During execution, at each step, it can choose to either 2 output a command (e.g., to use a tool) or 3 create a custom tool that can help it solve the issue. In Live-SWE-Agent, we define a custom tool as a script that can be executed in the environment.
Next, based on the 4 environmental feedback message, 5 we specifically ask the agent to reflect upon the past steps and decide whether a tool should be created.
This loop is repeated until the agent has submitted a solution 6 to the initial problem.
SWE-bench Verified
SWE-bench Verified benchmark contains 500 software development problems where the goal is to successfully modify the repository given a problem description. SWE-bench Verified is validated by human developers to ensure each problem description has sufficient amount of information to solve the issue.